Answer in brief: Claude Fable 5 is a reminder that AI agent security is becoming runtime security. As frontier models become better at long-running coding, research, and tool-heavy workflows, the main risk surface moves beyond prompts and responses into files, commands, processes, tools, memory, network activity, and the system changes agents leave behind. The unit of risk is no longer a message. It is the workflow.
Claude Fable 5 landed with the kind of reaction every frontier model release now seems to trigger: benchmark screenshots, developer hot takes, pricing debates, safety questions, enterprise governance concerns, and a familiar feeling that the ceiling just moved again. The interesting part is not only that the model is stronger. Stronger models arrive every few months. What matters is the kind of work Fable 5 is being associated with: long-running coding tasks, complex software engineering, research workflows, tool use, memory, and agentic execution.
Recent reporting around Fable 5 makes that shift visible. Axios reported that Fable 5 access was restored after U.S. export restrictions were lifted, while Tom's Hardware described a new safeguard path around prompts that could identify vulnerabilities and produce exploit code. Separately, The Verge reported that Microsoft restricted internal employee use over data retention concerns. Whether the focus is model capability, cyber misuse, or enterprise data governance, the same lesson keeps appearing: once agents move from answering questions to taking actions, safety becomes an execution-layer problem.
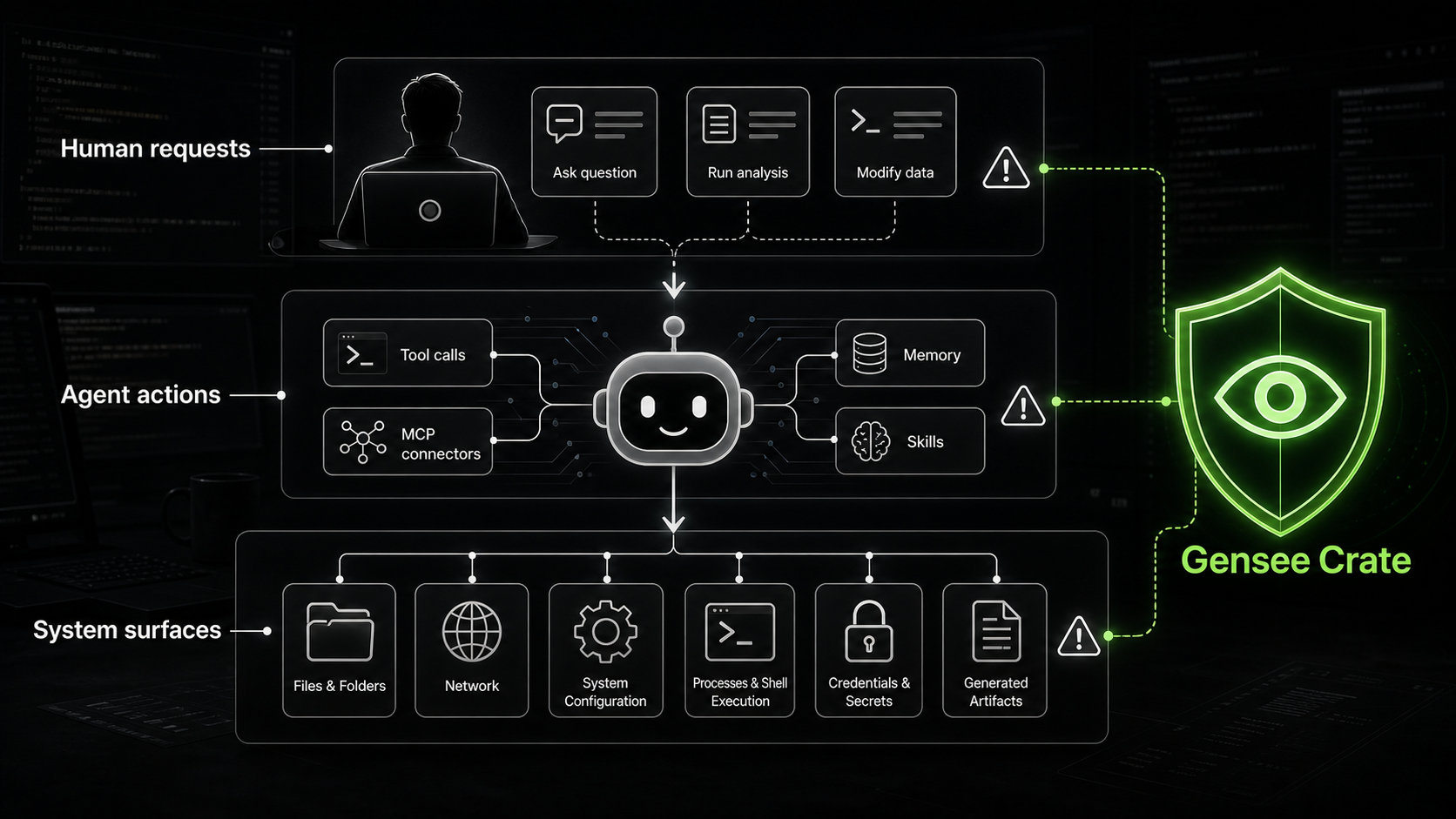
AI agent security is not just prompt security. Prompt and model safeguards are necessary, but they sit upstream from the place where agent risk becomes real: the runtime environment where files are read, commands run, tools execute, memory influences behavior, and system state changes.
What is AI agent runtime security?
AI agent runtime security is the practice of observing, attributing, governing, and preserving evidence around the actions an AI agent takes while it is operating. For a coding agent, that means tracking the relationship between the user request, agent tool calls, shell commands, file reads and writes, process trees, network behavior, memory access, policy decisions, and downstream artifacts. It is not a replacement for model safeguards. It is the layer that watches what happens after a capable model starts acting inside an environment.
For years, most AI safety conversations were shaped around the prompt and the response. Did the model reveal something it should not? Did it hallucinate? Did it generate harmful instructions? Did the user jailbreak the system prompt? Those questions still matter, but they no longer cover the full risk surface. A capable agent does not stop at language. It enters the workspace, opens terminals, installs dependencies, edits files, runs tests, follows errors into config, calls APIs, and may touch secrets or sensitive systems by accident.
This changes the unit of analysis. In a chatbot, the risky object is often a message. In an agentic workflow, the risky object is a chain of actions. A package install can execute scripts. A config read can expose credentials. A shell command can spawn child processes. A generated patch can create an authorization bypass. A test can pass while the agent quietly violates a constraint the developer forgot to restate. The transcript tells us what the agent appeared to be doing. The machine tells us what happened.
The agent is becoming part of the execution environment
A coding assistant used to feel like a smart pair programmer sitting beside the developer. The newer generation feels closer to a junior engineer with a terminal, a repo, a browser, and increasing patience. That is productive because many software tasks really are sequences of search, edit, run, interpret, and retry. It is also why the boundary between "AI output" and "system operation" is getting thinner.
Consider a normal agentic coding session. The developer asks for a migration or bug fix. The agent searches the repository, runs a command, sees an error, edits a config file, installs a package, triggers a build step, modifies tests, then retries. Nothing about that sequence is exotic. It is how software work happens. The risk lives in the same ordinary motion, which is why security teams need to understand the agent's path through the environment rather than only the text it produced along the way.
The important evidence sits in the chain: the session, the tool call, the process tree, the files touched, the sensitive resources approached, the network behavior that followed, and whether similar patterns return later. A transcript alone cannot carry that burden. Runtime security exists because agents create side effects.
Model safeguards are necessary, but they are upstream
Model providers will keep improving safeguards, and they should. Stronger models require stronger filtering, refusal behavior, monitoring, red teaming, and safety infrastructure. Reports about Fable 5 highlight exactly this pressure: the model was discussed not only in terms of capability, but in terms of cybersecurity misuse, government review, and data governance. That is a rational response to more capable models.
But model safeguards sit upstream from many enterprise failures. An agent can behave safely at the language layer and still create risk through tool use. It can follow a benign instruction and break an environment. It can make a reasonable local decision that becomes unsafe when combined with other actions. It can produce a patch that looks clean until someone traces how it was generated, which files it consulted, and what assumptions it made about credentials, permissions, or deployment state.
The troubling failures in coding-agent workflows are often operational rather than cinematic. They look like constraint violations, destructive file operations, authorization mistakes, command failures, environment breakage, and agents reporting success when the work is not actually safe or complete. The danger is not always a dramatic jailbreak. Sometimes it is a confident agent taking one extra step in the wrong directory.
Enterprises will not standardize on one clean agent stack
A neat security diagram usually assumes the agent is built inside a framework, instrumented from day one, and fully governed by the team deploying it. Real adoption is messier. Developers will use Claude Code, Cursor, Copilot-style tools, open-source CLIs, internal scripts, MCP servers, browser helpers, and custom automation. Some agents will expose hooks. Some will run through IDEs. Some will launch shells. Some will inherit local credentials. Some will be approved by security. Others will arrive because a team found that they work.
This is how developer tools spread. They do not wait for the architecture committee to finish the swimlane diagram. That mess creates a hard problem for agent security. SDK-level governance helps when the enterprise controls the agent, but it becomes weaker when the agent is a third-party tool, a local CLI, or a fast-moving developer workflow. Prompt monitoring can catch some intent, but it cannot reliably prove which child process touched which file. Endpoint logs can show system events, but they often lack agent context.
The useful layer has to connect both sides. Hooks, launchers, IDE context, operating-system signals, workspace changes, and session history all provide different pieces of evidence. None is perfect alone. Together, they can tell a credible story about what the agent caused. That is the direction agent security needs to take: less faith in a single control point, more layered evidence.
The missing primitive is attribution
Attribution sounds dry until something goes wrong. A sensitive file was opened. Was it the developer, the agent, a shell the agent spawned, a package script, a background process, an IDE extension, or a test runner? Without attribution, security teams get a pile of events and a headache. With attribution, they get a trail.
For AI agents, the trail has to preserve causality. A session began in a repo. A tool call led to a shell. The shell spawned another process. That process touched a credential path. A network connection appeared shortly afterward. Maybe the sequence is harmless. Maybe it is exactly the kind of behavior the team wants to review. The point is that the system can show how the pieces relate.
Confidence also matters. A hook event tied directly to an agent session is strong evidence of intent. A process tree gives strong evidence of system effect. A workspace change inferred only through timing is weaker. A good agent security layer should not blur those differences into the same red badge. Security teams learn to ignore tools that pretend every guess is a fact. Agent security will need more humility than that: expose the chain of evidence and the confidence behind it.
The data retention debate is part of runtime governance
The enterprise reaction to Fable 5 is not only about capability. It is also about governance. The Verge's reporting on Microsoft's internal restriction centered on Anthropic's data retention requirements for Fable 5, including retention for safety classifiers and longer retention for flagged content. That is not the same problem as shell execution, but it belongs to the same family of concerns: what data leaves the environment, who can access it, how long it is kept, and what evidence exists when something sensitive is involved.
The more valuable the agent, the closer it moves to sensitive work. The closer it moves to sensitive work, the more companies need visibility, auditability, and control. Banning frontier agents entirely is rarely a durable strategy. Letting them roam without an execution record is worse. The practical middle path is governed adoption: allow useful agents, constrain their environment, observe what they do, preserve evidence, and build policies that match real behavior rather than imaginary diagrams.
How teams should think about agent runtime security
Teams evaluating coding agents should ask questions that go beyond model selection. What files can the agent read or write? What commands can it run? What tools can it call? What memory can influence future actions? How are process trees attributed back to agent sessions? What happens before a risky operation executes? What evidence remains after a session ends? How does the system distinguish a direct agent action from a child process, package script, test runner, or IDE extension?
Those questions do not replace prompt safety. They make prompt safety operational. A model policy can say what the agent should not do, but runtime security shows what the agent actually attempted, what the environment allowed, and what happened afterward. In other words, the runtime record becomes the bridge between acceptable-use policy and real engineering behavior.
Our view at Gensee Crate
At Gensee Crate, we see agent security moving toward the execution layer. Model providers will keep improving safeguards. Cloud platforms will keep tightening identity, access, and data controls. Enterprises will keep writing usage policies. All of that is necessary. The open problem is what happens on the machine, in the workspace, and across the agent session once the model starts acting.
That layer needs to be close to runtime. It needs to understand process lineage, file activity, tool execution, sensitive resource access, memory influence, and session history. It needs to work even when the agent is not built inside a single controlled framework. It needs to help teams see what the agent attempted, what actually happened, and how much confidence they should place in the connection between the two.
Fable 5 is a reminder that agent capability is advancing faster than most companies' internal controls. The gap will not be solved by another acceptable-use policy pasted into a wiki. Teams need a runtime record of agent behavior that developers can understand and security teams can trust. The companies that adopt agents well will not be the ones that pretend risk disappears when the model gets smarter. They will be the ones that build the safety layer early enough for agentic work to scale.
Agent safety should go deeper and longer. Deeper into files, commands, tools, memory, process lineage, and system events. Longer across requests and sessions, where risk often emerges as a sequence rather than a single event.
Gensee Crate is built for teams taking that transition seriously. If you are deploying coding agents, internal AI workflows, or autonomous tools that touch sensitive environments, we would love to compare notes.
Frequently asked questions
Why is AI agent security becoming runtime security?
AI agent security is becoming runtime security because capable agents do more than generate text. They read files, run commands, call tools, use memory, spawn processes, and change software environments. The main risk is often the workflow and its side effects, not a single prompt or response.
What does Claude Fable 5 show about agent security?
Claude Fable 5 shows that stronger frontier models are being evaluated not only as answer engines but as workers inside coding and research environments. That pushes security attention toward runtime visibility, tool execution, data retention, attribution, and provenance.
Are model safeguards enough for AI agents?
Model safeguards are necessary but not enough. They sit upstream from many enterprise failures. An agent can pass language-layer safety checks and still create risk through file access, shell execution, tool calls, memory, package scripts, or generated code with unsafe side effects.
What is attribution in AI agent security?
Attribution means connecting system events back to the agent action that caused them. A useful agent security layer should show whether a file read, process, network connection, or workspace change came from the developer, the agent, a child process, a package script, or another tool.
How does Gensee Crate approach agent runtime security?
Gensee Crate focuses on runtime visibility, attribution, lineage, and provenance for coding agents. It helps teams understand what an agent attempted, what actually happened in the environment, and how actions connect across tools, sessions, memory, and system events.
Sources
This post refers to reporting from Axios, Tom's Hardware, The Verge, and Business Insider on Claude Fable 5, Mythos-class restrictions, safeguards, and enterprise data-retention concerns.