For most of the last few years, "AI safety" meant making sure a chatbot didn't say something it shouldn't. That framing is now out of date.
Modern AI agents don't just answer — they act. They hold API keys, browse the web, read your files and email, execute code, deploy software, send messages, and run 24/7 on your behalf. That autonomy is exactly where the value comes from. It is also exactly where the risk comes from.
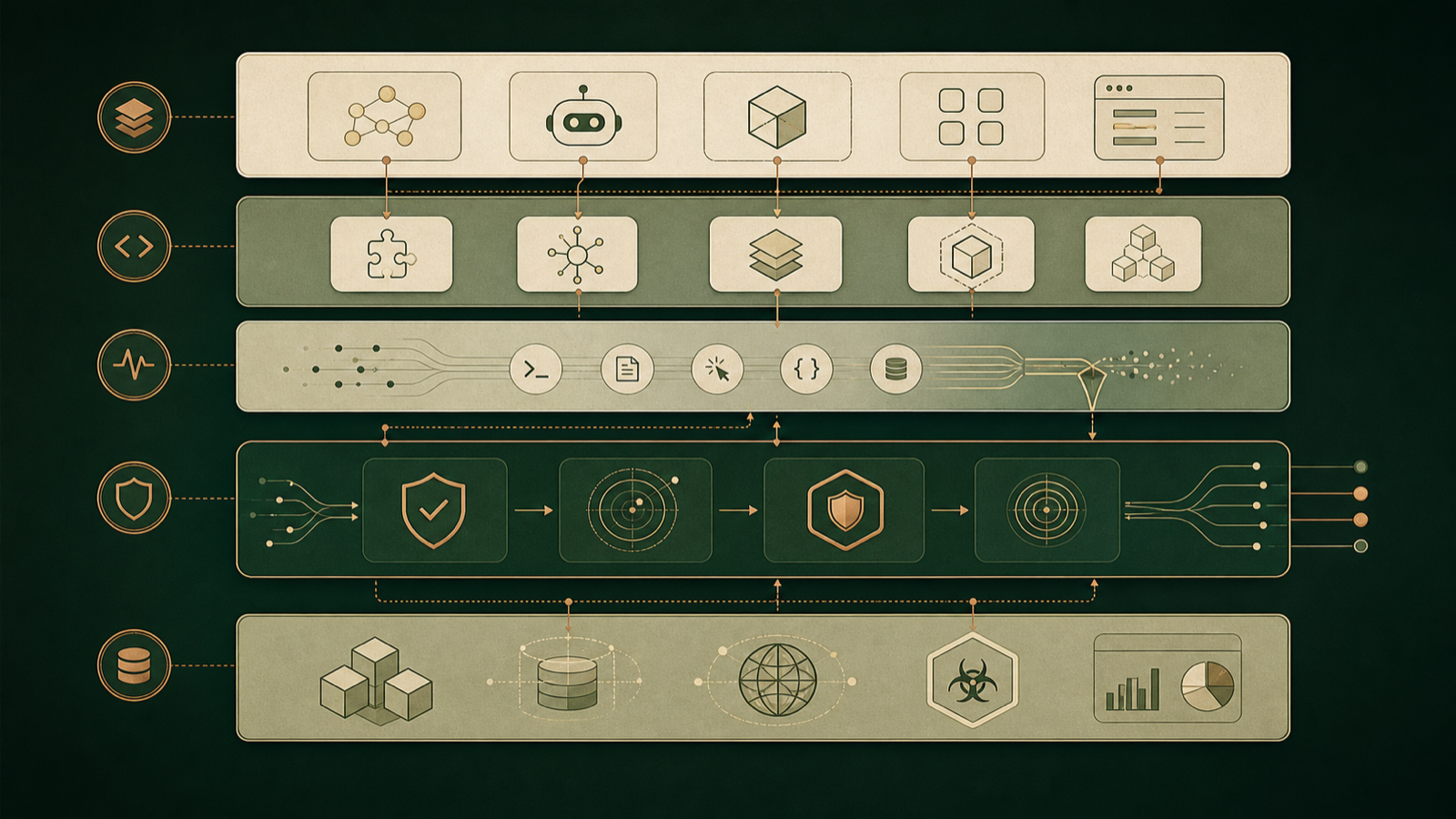
This post is a practical, vendor-neutral guide to AI agent security: the real problems people and businesses run into, the defenses that actually work, and the emerging discipline of ADR — Agent Detection and Response.
What is AI agent security?
AI agent security is the practice of protecting AI agents — and everything they can access or act upon — from misuse, mistakes, and attacks while they autonomously take actions on a user's behalf.
It is related to, but distinct from, two things people already know:
- Chatbot / LLM safety is about the text a model generates — toxicity, misinformation, jailbreaks.
- Traditional application security is about deterministic code — a program does exactly what it was written to do, every time.
Agent security sits in between and is harder than both, because an agent combines three properties at once: non-deterministic reasoning (it decides what to do), real-world tool access (it can do it), and persistent autonomy (it keeps doing it without you watching). The same prompt can produce different actions on different days, and some of those actions are irreversible.
What problems do individuals face when they rely on AI agents?
When a single person hands real tasks to an agent, the most common problems are not science-fiction "rogue AI" scenarios. They are mundane, high-frequency, and often self-inflicted:
- Credential and secret leakage. Pasting API keys, tokens, passwords, or wallet keys into a prompt — where they can end up in logs, tool calls, or third-party services. This is the single most common real-world issue.
- Excessive agency (over-reach). The agent does more than you asked: installs software, runs
sudo, opens network connections, or signs up for services that had nothing to do with the original request. - Irreversible actions. Deleting files, overwriting work, sending an email or message, or placing a trade — actions that can't be undone once taken.
- Prompt injection from untrusted content. A web page, email, or document the agent reads contains hidden instructions that hijack its behavior.
- Financial exposure. Trading bots, payment flows, and "buy this for me" automations turn a small mistake into real money lost.
- Privacy creep. An agent connected to your inbox, calendar, and files can read and transmit far more than you intended.
What problems do businesses face when they run AI agents at scale?
For a platform or business running many agents — or hosting agents for thousands of users — the individual risks above still apply, but new, structural ones appear:
- Multi-tenant blast radius. Many users share infrastructure. One compromised or abusive agent can affect neighbors if isolation is weak.
- Coordinated, cross-session abuse. A single session looks harmless. A hundred related accounts running the same script reveal a spam factory, a credential-farming ring, or a reward-farming operation.
- Compute and quota abuse. Bad actors use your platform's models and compute to do their own work — crypto mining, mass messaging, scraping — on your bill.
- Compliance and liability. When an agent acts on a customer's behalf, who is responsible for what it did? Audit trails and controls become a legal necessity, not a nice-to-have.
- Supply-chain and tool risk. Every connected tool, plugin, or MCP server is a new trust boundary the agent can be steered through.
- Lack of visibility. Without monitoring, you simply don't know what your fleet of agents is doing until something breaks publicly.
What are the main AI agent threats?
It helps to name the threat categories explicitly. Here is a compact taxonomy of the risks above, with who they tend to hit hardest:
| Threat | What it looks like | Who it hits |
|---|---|---|
| Credential exposure | API keys, tokens, and secrets surfaced in prompts, logs, or tool outputs | Individuals & platforms |
| Excessive agency / over-reach | Unrequested installs, sudo, privilege escalation, network calls beyond the task | Individuals & platforms |
| Prompt injection | Hidden instructions in web pages, emails, or files that hijack the agent | Individuals & businesses |
| Unsafe execution | curl | bash, rm -rf, deploying untested code to production | Individuals |
| Coordinated cross-session abuse | Many accounts running similar abuse — spam, farming, manipulation | Platforms |
| Data exfiltration | Agent reads sensitive data and sends it somewhere it shouldn't | Businesses |
| Platform abuse by malicious users | Using a platform's models/compute for harmful or prohibited tasks | Platforms |
How can you defend AI agents?
There is no single control that makes an agent safe. Effective agent security is defense-in-depth — several independent layers, so that when one fails the others still hold:
- Least privilege & scoped credentials. Give the agent only the access a task needs, and prefer short-lived, narrowly scoped tokens over long-lived master keys.
- Approval gates for high-risk actions. Require a human "yes" before installing software, escalating privileges, accessing the network, spending money, or doing anything irreversible.
- Secret hygiene & scanning. Detect leaked keys and tokens before they leave the system, and rotate anything that does.
- Isolation & sandboxing. Run each agent (and ideally each user) in an isolated, ephemeral environment so a bad action can't spread.
- Allow-lists. Constrain which tools, commands, and domains an agent can reach, rather than trying to block every bad one.
- Behavioral baselines. Learn what is normal for a given agent or user, so you can flag the abnormal.
- Cross-session correlation. Look across many sessions and accounts to catch coordinated abuse a single session would never reveal.
- Continuous monitoring, audit logs & a kill switch. Record what agents do, watch it in real time, and be able to stop a misbehaving agent instantly.
What is ADR (Agent Detection and Response)?
ADR (Agent Detection and Response) is continuous monitoring, detection, and automated response for the actions AI agents take. It is the agent-economy counterpart to EDR (Endpoint Detection and Response) and XDR — but instead of watching devices, it watches agents.
The defenses above are the building blocks. ADR is the operating layer that ties them together at runtime. A mature ADR approach generally rests on three pillars:
- Behavioral fingerprinting. Every agent — and every user behind it — develops a recognizable style: how requests are phrased, which tools get called, when activity happens, how often actions are approved. ADR builds a baseline and flags meaningful deviations in real time.
- Cross-session detection. ADR correlates activity across sessions and accounts, so that "create a Telegram bot" once looks fine, but the same pattern across a hundred linked accounts is recognized as a coordinated operation.
- Real-time response. Detection without action is just a dashboard. ADR can require approval for, throttle, contain, or block a risky action — and suspend an account — while it is happening, not after.
ADR vs. EDR: how they compare
If you know endpoint security, the analogy is direct. In the agent economy, the agent is the new endpoint:
| EDR (endpoints) | ADR (agents) | |
|---|---|---|
| Protects | Laptops, servers, devices | AI agents and the actions they take |
| Signal | Process, file, and network telemetry | Reasoning traces, tool calls, approvals, cross-session patterns |
| Threats | Malware, intrusion, lateral movement | Over-reach, credential leakage, prompt injection, coordinated abuse |
| Response | Isolate host, kill process, quarantine | Require approval, throttle, contain action, suspend account |
Why rules alone aren't enough
It is tempting to think agent security is just a big blocklist — regexes for API keys, a banned-command list, a deny-list of domains. Rules are necessary and catch the obvious cases, but they are not sufficient.
In large-scale production analysis of AI agents, only a minority of confirmed issues — on the order of 40% — can be caught by static rules alone. The rest require context and reasoning: was that sudo command something the user actually asked for, or autonomous over-reach? Is this secret a placeholder in example code, or a live key being leaked? Judging intent is exactly the kind of problem that needs model-level understanding layered on top of rules.
The practical takeaway: combine fast, deterministic rules with slower, reasoning-based judgment. Rules for coverage and speed; an LLM-based judge for the gray areas.
What the data says: credential exposure is the real #1 threat
The headlines focus on jailbreaks and prompt injection. The production data tells a less dramatic but more useful story.
In a large-scale study of AI agents spanning more than 10 months, 7,200+ hosts, and 10,000+ daily agent sessions, the single most frequent confirmed security issue was not prompt injection or jailbreaks — it was credential exposure: users and agents accidentally surfacing API keys, tokens, and secrets. Prompt injection, by contrast, was surprisingly rare in real production traffic.
That has a clear implication for where to spend effort first: prioritize secret detection and behavioral anomaly detection — catching unusual data-access and exfiltration patterns before they complete — ahead of exotic jailbreak defenses. Secure the boring, common failure mode before the rare, dramatic one.
A practical AI agent security checklist
For individuals
- Connect only the accounts and tools a task actually needs.
- Prefer agents and platforms that ask for approval before risky actions.
- Never paste long-lived secrets into a prompt; use scoped, rotatable keys.
- Watch for over-reach — if the agent starts installing or configuring things you didn't ask for, stop it.
- Run agents in isolated environments, not on your primary machine with full access.
For businesses and platforms
- Enforce per-tenant isolation and least-privilege tool access.
- Scan for leaked secrets continuously, and rotate on detection.
- Build behavioral baselines and correlate across sessions to catch coordinated abuse.
- Keep complete audit logs and an incident-response path with a real kill switch.
- Treat ADR as a first-class layer of the platform — not a dashboard bolted on afterward.
How GenseeAI approaches agent security
At GenseeAI, security is built into the agent platform rather than bolted on as a separate dashboard. That means the same three ADR pillars run natively where the agents actually execute:
- Behavioral fingerprinting per user, so the platform learns what "normal" looks like and flags deviations.
- Cross-session abuse detection, so coordinated patterns across many accounts surface even when each session looks benign.
- Platform-native approval primitives — high-risk actions like privilege escalation or network access pass through explicit approval flows by design.
Because these primitives live in the agent runtime, they scale to consumers and small teams — not just enterprises with dedicated security staff. The agent economy is arriving fast; the platforms that make agents safe by default are the ones it can be built on.
Frequently asked questions
What is AI agent security?
AI agent security is the practice of protecting AI agents — and everything they can access or act upon — from misuse, mistakes, and attacks while they autonomously take actions on a user's behalf. It is harder than chatbot safety or traditional app security because agents combine non-deterministic reasoning, real tool access, and persistent autonomy.
What is the biggest AI agent security threat?
In production, the most frequent confirmed issue is credential exposure — accidentally surfacing API keys, tokens, and secrets — followed by excessive-agency mistakes. Prompt injection and jailbreaks get more attention but are rarer in real traffic.
What is ADR (Agent Detection and Response)?
ADR is continuous monitoring, detection, and automated response for the actions AI agents take — the agent-economy counterpart to EDR/XDR. It combines behavioral fingerprinting, cross-session detection, and real-time response (approval, throttling, containment).
How is ADR different from EDR?
EDR protects endpoints by watching process, file, and network telemetry. ADR protects agents by watching reasoning traces, tool calls, approvals, and cross-session patterns. In the agent economy, the agent is the new endpoint, so ADR fills the role EDR fills for devices.
How do I keep my AI agent safe?
Use least-privilege scoped credentials, require approval for high-risk actions, scan for leaked secrets, isolate the agent's environment, allow-list its tools and domains, and monitor behavior continuously with audit logs and a kill switch. Agent security is defense-in-depth — no single control is enough.
Can prompt injection break my AI agent?
Yes — hidden instructions in web pages, emails, or files can hijack an agent that reads untrusted content. It is less common than credential exposure in practice, and you defend against it by isolating untrusted content, allow-listing tools and domains, and gating high-impact actions behind approval.