Short answer: the AI agent safety ecosystem is the set of controls that keep agentic systems from making unsafe, unauthorized, or untraceable actions. It spans model-level safeguards, prompt and app security, model asset security, red teaming, Tool/MCP security, sandboxes, runtime agent safety, agent identity, governance, and the traditional security stack.
That definition matters because the category is getting noisy. Some vendors secure prompts. Some secure models. Some run sandboxes. Some govern identity. Some watch tools. Some detect and respond at runtime. All of those matter, but they do not solve the same problem.
We made the map below to separate the layers clearly.
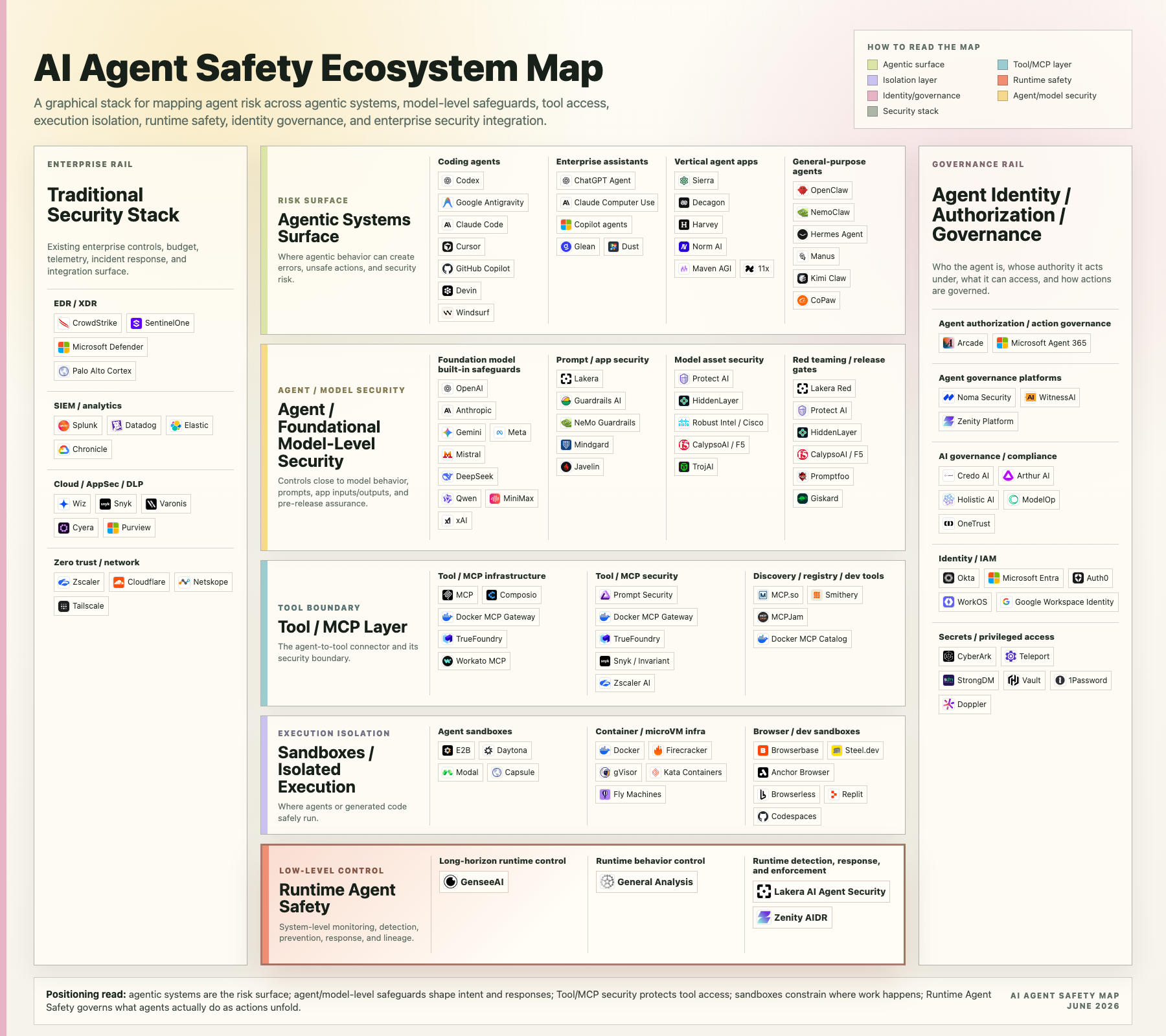
Agent safety is not one market. It is a stack. The right question is not "who secures agents?" but "which layer of the agentic system does this control actually secure?"
What is the AI agent safety ecosystem?
The AI agent safety ecosystem is the collection of products, infrastructure, and governance layers that reduce risk when AI agents reason, call tools, access data, execute code, and act on behalf of users or organizations.
This is different from classic chatbot safety. A chatbot can produce a bad answer. An agent can produce a bad outcome. It can click a button, call an API, trigger a workflow, modify a file, open a browser, expose a secret, or keep operating across a long-horizon task after the user has stopped watching.
That is why agent safety cannot live only in the model. It has to follow the action path:
- What is the model allowed to infer or say?
- What tools can the agent discover and call?
- Where does the agent execute code or browser actions?
- Whose identity and authority does the agent use?
- What happens while the agent is acting?
- Can the organization detect, prevent, respond, and reconstruct what happened?
The map is organized around those questions.
The agentic systems surface: where risk begins
At the top of the map is the agentic systems surface. This is not a safety layer. It is the surface where unsafe behavior can happen.
It includes coding agents, enterprise assistants, vertical agent applications, and general-purpose agents. Examples include products like Codex, Google Antigravity, Claude Code, Cursor, GitHub Copilot, Devin, ChatGPT Agent, Claude Computer Use, Glean, Dust, Sierra, Decagon, Harvey, OpenClaw, Hermes Agent, Manus, Kimi Claw, and CoPaw.
The point is not that these systems are inherently unsafe. The point is that they all share the same structural property: they are no longer just generating text. They are connected to workflows, tools, files, browsers, APIs, or other systems where mistakes have consequences.
Why call it a risk surface instead of "agents we protect"?
Because the goal is not to protect the agent as an object. The goal is to guard against error, misuse, and unsafe outcomes inside an agentic system. The agent, user, tools, model, memory, permissions, and execution environment all shape the risk.
Agent and foundational model-level security
The first security layer is closest to the model and the application logic. It includes:
- Foundation model built-in safeguards, such as safety behavior built into OpenAI, Anthropic, Gemini, Meta, Mistral, DeepSeek, Qwen, MiniMax, and xAI models.
- Prompt and app security, including prompt injection defense, content filtering, input/output inspection, and policy enforcement around model interaction.
- Model asset security, including scanning, inventory, model supply-chain security, adversarial testing, and protection of model artifacts.
- Red teaming and release gates, where systems are tested before release against jailbreaks, misuse, prompt injection, data leakage, and other failure modes.
This layer is necessary, but it is not sufficient. A model safeguard can reduce harmful responses. It cannot fully control what happens after an agent has already chosen to call a tool, run code, or act through a browser.
Model-level security reduces unsafe intent and unsafe output. Runtime agent safety reduces unsafe action. Both are required for high-agency systems.
Tool and MCP security
The next layer is the Tool/MCP boundary: the place where an agent turns language into action.
MCP servers, tool gateways, connector platforms, registries, and catalogs make agents useful. They also create a new security boundary. Once an agent can discover a tool, authenticate into it, read its output, and call it repeatedly, prompt safety is no longer enough.
Tool and MCP security answers questions like:
- Which tools can this agent see?
- Which tools can it call without approval?
- What permissions does each tool carry?
- Can tool output inject instructions back into the agent?
- Can a malicious or compromised MCP server exfiltrate data?
- Can the organization audit which tool call caused which side effect?
This is why the map separates Tool/MCP infrastructure from Tool/MCP security. Infrastructure makes tool use possible. Security makes tool use governable.
Sandboxes and isolated execution
Sandboxes answer a different question: where does the agent run?
Agents increasingly execute code, browse websites, manipulate files, run terminal commands, and use dev environments. Without isolation, one unsafe action can affect the user's machine, production systems, credentials, or neighboring tenants.
The sandbox layer includes agent sandboxes, container and microVM infrastructure, browser sandboxes, and developer environments. These controls constrain blast radius. They do not decide whether an action is wise, but they can limit how far damage spreads when something goes wrong.
That distinction matters: a sandbox is not runtime reasoning. It is execution containment.
Runtime agent safety: the low-level control layer
Runtime agent safety is system-level monitoring, detection, prevention, response, and lineage for agentic systems while actions unfold.
This is the layer where GenseeAI sits. In the map, GenseeAI is placed under long-horizon runtime control, which is the part of runtime safety focused on agents that operate across many steps, tools, sessions, and state transitions.
Why does this layer need to exist? Because many agent failures are not visible at prompt time. They emerge from sequences:
- The first tool call is harmless; the fifth one creates a risky state change.
- A browser action looks normal until it combines with an earlier extracted secret.
- A coding agent does the right thing locally, then deploys or deletes the wrong file.
- An agent stays within policy in each individual step but drifts away from the user's actual goal.
- A long-running task becomes unsafe because the environment changes while the agent is still operating.
Runtime safety is the control layer for those sequences. It watches actions as they happen, preserves lineage, and gives the system a chance to prevent, interrupt, roll back, or respond before a mistake turns into an incident.
Runtime safety vs. ADR
ADR, or Agent Detection and Response, is one way to describe part of this runtime layer. ADR focuses on detecting and responding to agent behavior. Runtime agent safety is slightly broader: it includes prevention, policy enforcement, lineage, long-horizon control, and recovery.
Agent identity, authorization, and governance
Agents need identities. They act on behalf of users, teams, services, or organizations. Without a clear identity and authorization model, every agent becomes a privileged shadow user.
The governance rail in the map includes agent authorization, action governance, agent governance platforms, AI governance/compliance, identity/IAM, secrets management, and privileged access management.
This layer answers:
- Who is the agent?
- Who authorized this action?
- Which user, service, or team does the agent represent?
- What can the agent access?
- Which actions require explicit approval?
- How are secrets issued, scoped, rotated, and revoked?
Identity governance is not a replacement for runtime safety. It defines the authority boundary. Runtime safety watches what happens inside that boundary.
The traditional security stack still matters
The left rail of the map is the traditional security stack: EDR/XDR, SIEM and analytics, cloud security, AppSec, DLP, zero trust, and network security.
This stack does not disappear in the agent era. It becomes an integration surface. Agent safety systems need to produce signals that security teams can understand: alerts, traces, incidents, user context, tool-call lineage, policy decisions, and response events.
The traditional stack is also where budgets, SOC workflows, compliance programs, and incident response processes already live. The winning agent safety products will not ask enterprises to abandon those systems. They will connect agent-specific telemetry into them.
AI agent safety categories at a glance
| Layer | Primary question | What it controls |
|---|---|---|
| Agentic systems surface | Where can unsafe behavior happen? | Agent products, assistants, vertical apps, coding agents, general-purpose agents |
| Agent/model-level security | Can we reduce unsafe model behavior and app-level misuse? | Model safeguards, prompt security, model asset security, red teaming |
| Tool/MCP security | Can the agent safely call tools? | MCP servers, tool gateways, connector permissions, tool output, registries |
| Sandboxes | Where can the agent execute? | Containers, microVMs, browser sandboxes, dev sandboxes, isolated environments |
| Runtime agent safety | Can we prevent and respond while actions unfold? | Monitoring, detection, prevention, response, lineage, long-horizon control |
| Identity/governance | Who is the agent and what can it do? | Agent identity, authorization, secrets, privileged access, AI governance |
| Traditional security stack | How does this fit enterprise security operations? | EDR/XDR, SIEM, DLP, cloud security, AppSec, zero trust, SOC workflows |
How to evaluate an AI agent safety vendor
When a vendor says they do "agent security," ask which layer they operate in. Then ask what happens before, during, and after an action.
Before action
- Does the system reduce unsafe prompts or model outputs?
- Does it red-team agent behavior before release?
- Does it define tool permissions and identity boundaries?
During action
- Can it observe tool calls, browser actions, code execution, and state changes?
- Can it prevent or interrupt risky behavior before completion?
- Can it reason over a long-horizon sequence instead of one isolated step?
After action
- Can it reconstruct what happened?
- Does it preserve lineage across prompts, tools, actions, and outcomes?
- Can it feed incidents into SIEM, SOC, governance, or audit workflows?
If a product only answers one of these phases, it may still be useful. But it should be named honestly. Prompt security is not runtime safety. A sandbox is not governance. Governance is not action-level prevention. Runtime control is not a model safeguard.
Where GenseeAI fits
GenseeAI is focused on long-horizon runtime control: the low-level control layer for agentic systems that need system-level monitoring, detection, prevention, response, and lineage.
That is the layer we believe becomes essential as agents move from short chats into long-running work. The harder problems are no longer isolated prompts. They are sequences of actions across tools, identities, browser states, code environments, memories, and user intent.
In that world, safety has to be close to execution. It has to understand what the agent is doing, what changed, which authority was used, which tools were involved, and whether the behavior still matches the user's goal and the organization's policy.
Frequently asked questions
What is the AI agent safety ecosystem?
The AI agent safety ecosystem is the set of controls, vendors, infrastructure layers, and governance systems used to reduce risk in agentic systems. It includes model-level safeguards, prompt and app security, model asset security, red teaming, Tool/MCP security, sandboxes, runtime agent safety, agent identity, AI governance, and the traditional security stack.
What are the main layers of AI agent safety?
The main layers are the agentic systems surface, agent/foundational model-level security, Tool/MCP security, sandboxes and isolated execution, runtime agent safety, agent identity and governance, and enterprise security integrations such as EDR, XDR, SIEM, cloud security, AppSec, DLP, and zero trust.
Why is runtime agent safety important?
Runtime agent safety is important because agent failures often happen while an agent is taking actions, not just while a model is generating text. Runtime safety monitors behavior, detects risk, prevents unsafe actions, responds to incidents, and preserves lineage for investigation and rollback.
How is Tool/MCP security different from prompt security?
Prompt security focuses on inputs, instructions, and model behavior. Tool/MCP security focuses on the boundary where an agent calls tools, APIs, MCP servers, and external systems. It protects tool discovery, permissions, connector trust, tool output handling, and the actions agents can trigger through tools.
Where does GenseeAI fit in the AI agent safety ecosystem?
GenseeAI fits in runtime agent safety, especially long-horizon runtime control. That layer focuses on system-level monitoring, detection, prevention, response, and lineage for agentic systems while actions unfold.